They Completely Buried the Lede
So DeepSeek AI just released what’s probably the most misleadingly named paper of 2025. They called it “DeepSeek-OCR”, which, let’s be honest, sounds about as thrilling as “yet another document parser.” But here’s what they actually built: a 10-20× context compression system that completely flips the script on how vision and text tokens work in LLMs.
If you’re wrestling with long-context processing, building multimodal architectures, or desperately trying to shove entire codebases into LLM context windows; stop everything. You need to read this.

The Problem: Transformers Still Can't Handle Length
Look, the quadratic scaling of transformer attention has been AI’s Achilles’ heel since day one. Feed an LLM 100k tokens and you’ll immediately see:
Memory consumption exploding at \(O(n^2)\) activation memory
Computational costs spiraling as sequence length grows
Latency making real-time applications basically impossible
Token costs scaling linearly with every additional word
The industry’s been throwing the usual suspects at this problem: sparse attention mechanisms, sliding windows, hierarchical architectures. DeepSeek asked something completely different: What if we just… stop feeding it text tokens altogether?
The Inversion: Vision Tokens Are Now More Efficient Than Text
Here’s the thing—traditionally, vision tokens were the inefficient ones. Think about it: a 10,000-word document would balloon into:
15,000 text tokens using standard tokenization
30,000-60,000 vision tokens with traditional VLM encoding
Vision was basically an afterthought, a bolt-on for handling images. Nobody thought of it as a compression mechanism for text.
DeepSeek-OCR completely inverts this:
10,000-word document → 1,000 vision tokens (that’s 10× compression!)
20,000-word document → 1,000 vision tokens (20× compression!)
This isn’t just an incremental improvement. We’re talking about a fundamental paradigm shift in how we think about multimodal token efficiency.
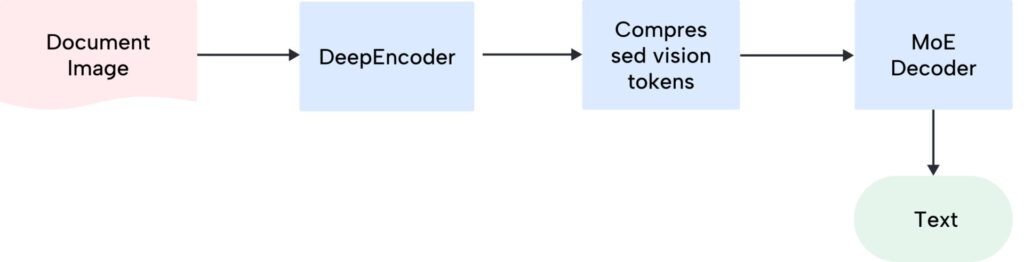
The Architecture: DeepEncoder + MoE Decoder
DeepEncoder: Hybrid Vision Compression (≈380M params)
The encoder is where the magic happens. It combines three components working in serial:
1. SAM-base (80M params): Handles window attention for local, fine-grained perception
2. 16× Convolutional Compressor: Aggressively reduces tokens before the heavy lifting
3. CLIP-large (300M params): Provides dense global attention for layout and context understanding
Here’s how the token flow works:

This architecture elegantly solves the activation memory explosion that’s been plaguing adaptive resolution encoders like Qwen2-VL. By compressing before global attention kicks in, DeepEncoder keeps memory footprint low even when you’re throwing high-resolution inputs at it.
DeepSeek3B-MoE-A570M: Sparse Expert Decoder
The decoder leverages a mixture-of-experts architecture that’s pretty clever:
64 total experts available
6 experts activated per token (sparse activation pattern)
570M active parameters during each inference step
This design lets the model specialize in different tasks—charts, formulas, multilingual text—while keeping computational efficiency high.
The complete pipeline looks like this:
Performance Metrics: Nearly Lossless at 10× Compression
Fox Benchmark: Compression-Accuracy Tradeoffs
Compression Ratio | OCR Precision | What This Means in Practice |
|---|---|---|
9-10× | 97%+ | Effectively lossless compression |
10-12× | ~90% | High-fidelity for most real-world use cases |
20× | ~60% | Aggressive compression for archival/retrieval |
At 10× compression with 97% precision, we’re looking at functionally lossless performance for the vast majority of document processing tasks.
OmniDocBench: SOTA with Minimal Tokens
DeepSeek-OCR achieves state-of-the-art accuracy while using dramatically fewer tokens than anything else out there:
Model | Tokens/Page | Performance |
|---|---|---|
MinerU2.0 | 6,000+ | Baseline SOTA |
GOT-OCR2.0 | 256 | Strong performance |
DeepSeek-OCR | 100-800 | SOTA with fewest tokens |
Get this, in some configurations, DeepSeek-OCR processes an entire page with just 100 vision tokens. That’s less than what traditional OCRs burn through for a single paragraph.
Production Scalability: Industrial-Grade Throughput
Let’s talk real-world deployment numbers:
Single A100-40G GPU: 200,000+ pages per day
20-node cluster (160 A100s): 33 million pages per day
Training data generation: Massive-scale synthetic data production for LLM/VLM pretraining
This isn’t some research toy gathering dust in a lab. This is production-ready infrastructure for document processing at serious scale.
Technical Deep Dive: Why This Actually Works
Context Optical Compression Explained
The traditional approach has always been:

DeepSeek-OCR flips the script:
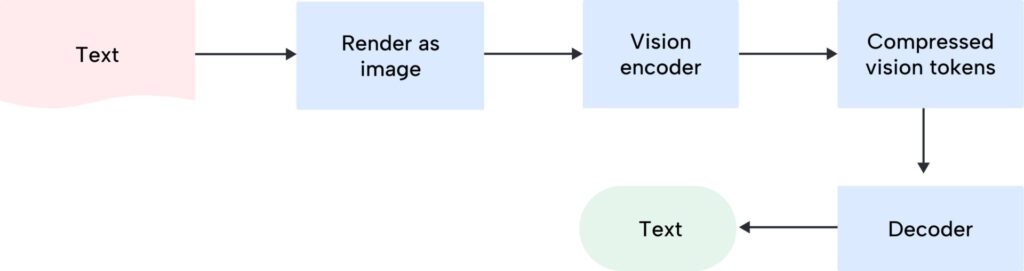
But why is this more efficient?
Language is inherently redundant. When you look at the visual form of a page, it encodes:
Spatial layout: Information density varies across different parts of the page
Typography: Font choices, sizes, and formatting all carry semantic meaning
Structure: Headers, paragraphs, lists—they’re all visually distinct
A vision encoder can map this 2D structure into a compact latent space way more efficiently than sequential text tokenization ever could.
Multi-Resolution Support
Here’s something cool – DeepSeek-OCR isn’t locked into one compression ratio. It supports multiple “modes” depending on what you need:
Low compression (high fidelity): For recent context and critical documents
Medium compression: Standard document processing workflows
High compression (aggressive): Archival storage and older context
This enables controllable memory decay mechanisms that actually mimic how human memory works:
Recent context: High-resolution, more tokens preserved
Older context: Downsampled, fewer tokens needed
Ancient context: Heavily compressed or just discarded
Beyond OCR: Extended Capabilities
DeepSeek-OCR handles way more than just plain text. It tackles complex document structures:
Structured Data Parsing
Charts and graphs → HTML table conversion
Chemical formulas → SMILES string generation
Geometric figures → Structured dictionary output
Mathematical notation → LaTeX/symbolic representation
Multilingual Support
100+ languages with consistent performance across all of them
Mixed-language documents without needing language-specific preprocessing
General Vision Capabilities
Image captioning and object grounding capabilities retained
Multimodal fusion without maintaining separate vision/text pipelines
Implications for LLM Architecture
1. Massive Context Windows Become Actually Practical
With 10-20× compression, context sizes that were previously pipe dreams suddenly become feasible:
Traditional approach:
100K token context → Quadratic memory scaling → Completely impractical
DeepSeek-OCR approach:
100K tokens → 5K-10K vision tokens → Manageable memory footprint
Effective context: 1-2 million tokens with visual compression
Potential ceiling: 10-20 million token contexts with optimized architectures
2. Real-World Use Cases That Were Impossible Before
Entire codebase in context:
Initial load: Compress entire codebase as visual snapshots
Updates: Append git diffs as text
Result: Full codebase context without RAG/search overhead
Corporate knowledge base:
Compress: All internal documentation as visual context
Cache: Store compressed representation
Query: Add specific question on top
Result: Fast, cost-effective knowledge retrieval
Historical document processing:
Archive: Compress historical documents at 20× ratio
Store: Minimal storage requirements
Retrieve: Decode on-demand with 60%+ accuracy3. Cost and Efficiency Benefits
Reduced inference cost: Fewer tokens → fewer FLOPs → lower operational costs
Faster processing: Compressed representations accelerate attention mechanisms
Memory optimization: Visual tokens enable efficient long-term storage
Bandwidth savings: Transmit compressed visual representations instead of raw text
Training Pipeline: Two-Stage Approach
Stage 1: DeepEncoder Pretraining
Objective: Optimize the vision encoder specifically for compression efficiency
Method: Next-token prediction on image-text pairs
Focus: Learning compact visual representations
Stage 2: Joint Encoder-Decoder Training
Objective: End-to-end optimization for OCR accuracy
Data mix:
OCR 1.0 data (30M pages): Real PDFs across 100+ languages
OCR 2.0 data: Synthetic but structured documents (charts, formulas, etc.)
General vision (20%): Maintaining image understanding capabilities
Text-only (10%): Preserving linguistic quality
Training Scale
Hardware: 20 nodes × 8 A100-40G GPUs
Throughput: 70-90 billion tokens processed per day
Batch size: 640 globally
Optimizer: AdamW with 3e-5 learning rate
The Fundamental Question Answered
For a document containing 1,000 words, how many vision tokens are minimally needed for decoding?
DeepSeek’s answer: 100-200 vision tokens (achieving 5-10× compression with 97% accuracy)
This empirically validates that “a picture is worth a thousand words” isn’t just some poetic metaphor—it’s a quantifiable compression ratio we can actually measure and optimize.
Open Source: Democratizing the Breakthrough
Unlike proprietary systems (Google’s Gemini probably uses similar techniques but keeps them locked down tight), DeepSeek has open-sourced the whole thing:
Available at: github.com/deepseek-ai/DeepSeek-OCR
What you get:
Complete model weights
Training code and entire data pipeline
Inference implementation
Benchmark evaluation scripts
What this enables:
Reproduction and validation of their results
Custom application development on top of the architecture
Community contributions and extensions
Production deployment without licensing headaches
Unanswered Questions and Future Directions
1. Reasoning Over Compressed Tokens
Can LLMs reason as effectively over compressed visual tokens as they can over regular text tokens?
The implications: If reasoning quality takes a hit, we’re looking at a tradeoff between context length and cognitive capability. That’s worth understanding deeply.
2. Lossy Compression Tradeoffs
What information actually gets lost in aggressive compression, and does it matter for downstream tasks?
Research direction: We need to characterize the semantic versus syntactic information preserved at different compression ratios.
3. Integration with Sparse Attention
The opportunity: Combine visual compression with DeepSeek’s recent sparse attention work for multiplicative efficiency gains.
The potential: 10× compression + 10× sparse attention = 100× effective context expansion. That’s not incremental—that’s transformative.
4. Multimodal Memory Architectures
The vision: LLMs with hierarchical memory systems that actually make sense:
Working memory: Text tokens (high fidelity, immediate access)
Short-term memory: Low-compression visual tokens
Long-term memory: High-compression visual tokens
Archival memory: Ultra-compressed or summarized representations
Why This Matters for OpenCraft AI
At OpenCraft AI, we’re building next-generation AI systems that absolutely require efficient long-context processing. DeepSeek-OCR validates our core thesis: multimodal compression is the path to practical long-context LLMs.
Here’s what we’re exploring:
Integration of visual compression directly into our production pipelines
Extensions for domain-specific document types (legal contracts, medical records, technical documentation)
Hybrid architectures that combine visual compression with retrieval-augmented generation
Memory mechanisms inspired by DeepSeek’s controllable forgetting paradigm
Conclusion: The Era of Visual Context Compression
DeepSeek-OCR isn’t just another OCR model. It’s a proof-of-concept for fundamentally rethinking how LLMs should process and store textual information.
Key takeaways:
Vision tokens can be 10-20× more efficient than text tokens for document content
97% accuracy at 10× compression makes this practically lossless for real applications
Production-ready scalability (200K+ pages/day on a single GPU)
Open source availability democratizes access to cutting-edge compression technology
Paradigm shift: Future LLMs may store long-term memory as compressed visual representations
For researchers, engineers, and technical leaders working on LLM infrastructure, this is required reading. The context length problem that’s been constraining LLM capabilities since the beginning may have just found its solution—and it’s not a bigger attention window. It’s a smaller vision.
The future of AI memory might not be stored in tokens at all. It might be stored in pictures—compressed, layered, and fading over time, just like our own memories.
New to this topic? Start with the simplified overview.
DeepSeek-OCR: Reshaping Document Processing for AI
OpenCraft AI is an India-based AI startup building smarter, more efficient AI solutions. We’re focused on making AI work better with real-world data. Follow our blog for more insights into emerging AI technologies explained in plain English—no jargon required.


