In this blog, we’ll dive into the groundbreaking technology behind DeepSeek-OCR, exploring how it revolutionizes document processing by compressing text into compact digital packages.
We’ll discuss the challenges AI faces with long documents, how DeepSeek-OCR flips traditional assumptions about text and image processing, and the practical applications of this technology.
From enhancing AI’s memory capabilities to reducing costs and improving speed, we’ll cover why this innovation is a game-changer for AI systems and what it means for the future of document handling.

A Deceptively Simple Name Hides Something Revolutionary
You know that feeling when someone tells you about something with the most boring name possible, and then it turns out to be absolutely game-changing? That’s DeepSeek-OCR.
On the surface, it sounds like just another tool for scanning documents. Yawn, right? But here’s where it gets interesting: they’ve figured out how to compress massive amounts of text into tiny digital packages that computers can process way faster and cheaper. It’s the kind of breakthrough that doesn’t make headlines but quietly changes everything behind the scenes.
If you’ve ever wondered why AI systems get sluggish with really long documents, or why they start charging you more the longer your text gets, this might be the answer you’ve been waiting for.
The Problem We've All Felt: AI Gets Tired With Long Documents
Picture this: you’re chatting with an AI, and you ask it to read a 100-page document and answer questions about it. What happens? The responses get slower. The system feels like it’s struggling. And if you’re paying per token “which many people are” your bill starts climbing like you’re taking a taxi through rush hour traffic.
Here’s the thing: the way AI processes text is kind of like trying to remember everything you’ve ever read while simultaneously reading something new. The more you read, the harder it gets to keep track of it all. Your brain gets tired. Well, computers face the exact same problem, except they get tired exponentially faster.
The tech industry’s been throwing everything at this problem. Sparse attention mechanisms. Sliding windows. Hierarchical architectures. All clever tricks, but they’re basically just rearranging deck chairs on the Titanic. DeepSeek asked something completely different: What if we didn’t make the computer read text at all?
The Flip: Images Are Actually Better Than Text (For Computers)
Here’s something that sounds totally backwards: computers have traditionally been better at understanding text than images. It’s counterintuitive, but it’s true. So when AI researchers wanted to compress information, they naturally stuck with text.
But DeepSeek discovered something that flips this assumption on its head. If you take a page of text and convert it into an image, then use a smart vision system to read that image, you can compress it way more efficiently than keeping it as text.
Think of it like this:
10,000 words as text = needs about 15,000 digital tokens (think of tokens as tiny pieces of information)
10,000 words as an image = needs only about 1,000 digital tokens
That’s a 10-15× reduction in size. For a computer, that’s not just better—that’s revolutionary.
It’s like discovering that instead of writing down every detail of a painting, you could just show the painting itself and take up less space.
How It Actually Works: The Two-Part System
DeepSeek-OCR is basically a two-step dance. First, it compresses. Then, it reconstructs. Let me break it down:
Part 1: The Vision Compressor (DeepEncoder)
Imagine a really smart system that looks at a document image and extracts only the essential information—kind of like a master summarizer, but for visual information. That’s what DeepEncoder does.
It works in three stages:
First, it looks at the fine details of the document. It’s like zooming in and examining individual words, formatting, and typography.
Then, it steps back and understands the big picture. How is the page laid out? Where are the headers? Where are the paragraphs? It’s like zooming out to see the overall structure.
Finally, it squeezes everything down into a compact digital representation. Think of it like taking a high-resolution photo and compressing it into a smaller file size without losing the important details.
Part 2: The Text Reconstructor (MoE Decoder)
Once the document is compressed into this tiny package, a second system reads those compressed signals and reconstructs the original text. Here’s the clever part: it’s not just one system. It’s like having a team of specialists—one expert for charts, another for chemical formulas, another for regular text, and so on.
The whole process looks like this:
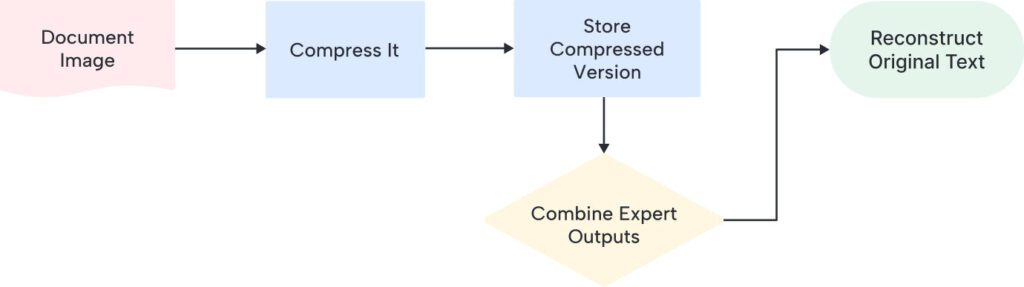
It’s elegant, really. Simple in concept, but sophisticated in execution.
The Numbers: Nearly Perfect Compression
Okay, here’s where it gets genuinely impressive. When researchers tested this system, the results were almost too good to believe:
Compression Level | Accuracy | What It Means |
|---|---|---|
10× smaller | 97% | Basically perfect—you won’t notice any loss |
12× smaller | 90% | Still very good for most real-world uses |
20× smaller | 60% | Good enough for archiving old documents |
At 10× compression with 97% accuracy, this is basically lossless. You get back almost exactly what you put in, just in a much smaller package. It’s like having a photocopier that makes copies 10 times smaller but they’re still readable.
Real-World Performance
Now let’s compare this to what else is out there:
System | Size Per Page | Quality |
|---|---|---|
Older systems | 6,000+ units | Good |
Competing systems | 256 units | Good |
DeepSeek-OCR | 100-800 units | Better than all of them |
Here’s the kicker: DeepSeek-OCR reads entire pages with less digital space than older systems needed for a single paragraph. It’s not just better—it’s in a different league.
Speed and Scale: It's Actually Practical
This isn’t just a cool research project that only works in a lab. It actually works at real-world scale:
One powerful computer: Can process 200,000 pages per day
A cluster of computers: Can handle 33 million pages per day
That’s not theoretical. That’s production-ready. That’s “we can actually use this” fast.
Why This Matters in Plain English
Bigger Context Windows
Right now, when you use an AI chatbot, there’s a limit to how much text you can feed it at once. It’s like having a conversation with someone who can only remember the last few minutes. This breakthrough could change that fundamental limitation.
Imagine being able to:
Upload an entire book and ask questions about it without hitting a wall
Feed your whole codebase to an AI and have it understand your entire project at once
Load all your company documents and search through them instantly, like you have a personal librarian
Have a conversation that remembers everything from the beginning without getting confused
Cheaper to Use
Less data to process means lower costs. If you’re paying for AI services—and many people are—this could significantly reduce your bills. It’s like discovering a way to do the same work with half the electricity.
Faster Responses
Smaller data packages mean faster processing. Your AI assistant could respond quicker, especially with long documents. No more waiting around for it to churn through massive amounts of text.
Better Memory
This approach could help AI systems remember more context from earlier in a conversation without getting bogged down. It’s like having a conversation partner who can recall details from hours ago without losing focus.
What It Can Actually Do
DeepSeek-OCR isn’t just for reading plain text. It’s surprisingly versatile:
Charts and graphs → Converting them into tables you can actually use
Chemical formulas → Understanding scientific notation and molecular structures
Diagrams and drawings → Interpreting visual information and technical drawings
Multiple languages → Works with 100+ languages without breaking a sweat
Mixed documents → Handles pages with text, images, and diagrams all jumbled together
It’s like having a universal translator for documents.
Real-World Applications You Can Actually Imagine
For Researchers
Digitize historical documents and archives without needing massive storage space. Compress old papers and retrieve them instantly when needed. Imagine having access to centuries of research without needing a warehouse to store it all.
For Businesses
Load all your internal documents, policies, and procedures into an AI system. Then ask it questions like you’re talking to an expert who’s read everything. “What’s our policy on remote work?” “How do we handle customer complaints?” Instant answers.
For Developers
Feed your entire codebase to an AI assistant. It understands your whole project and can help you code faster. No more context-switching between files. The AI has seen everything.
For Students
Upload textbooks and research papers. Ask the AI to summarize, explain, or find specific information. It’s like having a tutor who’s read all your materials and can answer any question.
For Legal Professionals
Process contracts and legal documents at scale. Search through thousands of pages instantly. Find precedents and relevant clauses without spending days reading.
The Human Memory Connection
Here’s something that’s genuinely fascinating: the way DeepSeek-OCR works is actually similar to how human memory functions.
When you remember a page from a book you read years ago, you don’t remember every single word. You remember the visual layout. You remember where things were on the page. You remember the general structure and the important bits. Your brain compresses information visually, storing the essence rather than every detail.
That’s exactly what DeepSeek-OCR does digitally.
And here’s where it gets even more interesting
your memory isn’t static. Recent memories are clear and detailed. You remember what you had for breakfast today. But what did you have for breakfast three years ago? Probably no idea. Your brain compresses older memories, keeping only the essential information.
This system can do the same thing – keeping recent information sharp and detailed, and compressing older information more aggressively. It’s like having a digital memory that works like a human brain.
The Open-Source Advantage
Here’s something that makes this even better: DeepSeek has made all the code and models freely available. This isn’t some proprietary black box that only one company can use.
This means:
Researchers can study how it works and improve it
Developers can build applications using this technology
Companies can use it without paying licensing fees
Everyone benefits from improvements the community makes
It’s the opposite of the usual tech industry playbook, where companies hoard their innovations like dragons guarding treasure. DeepSeek said, “Here’s what we built. Make it better. Make it yours.”
Questions Still Being Explored
While this breakthrough is impressive, there are still some open questions that researchers are wrestling with:
Does compressed information work as well for reasoning? When information is compressed, does the AI still reason about it as effectively as with regular text? Or does something get lost in translation?
What gets lost in compression? At very high compression levels, some information is definitely lost. Understanding what that is “and whether it matters” is important.
Can we combine this with other techniques? DeepSeek has other innovations that might work even better when combined with this compression approach. What happens when you stack multiple breakthroughs?
What about long-term memory? Could AI systems use this for memory that works more like human memory, recent events crystal clear, older events fading into the background?
These aren’t problems. They’re opportunities for the next wave of innovation.
Why OpenCraft AI Is Excited About This
At OpenCraft AI, we’re building AI systems that need to handle massive amounts of information efficiently. This breakthrough validates something we’ve believed all along: the future of AI isn’t about making bigger systems, it’s about making smarter systems that use information more efficiently.
We’re not just watching this breakthrough. We’re building on it.
The Bottom Line
DeepSeek-OCR represents a fundamental shift in how AI can work with documents. Instead of struggling with longer and longer texts, computers can now compress them intelligently and work with them more efficiently.
It’s not flashy. It won’t make the news. But it’s the kind of breakthrough that quietly changes everything.
Here’s what you should remember:
Computers can now compress text 10-20× smaller while keeping almost all the information
This works nearly perfectly at 10× compression (97% accuracy)
It’s fast enough for real-world use (millions of pages per day)
It’s open source, so anyone can use it
This could change how AI handles documents forever
The future of AI might not be about bigger models or longer context windows. It might be about smarter compression—storing information the way our brains do, in visual snapshots that fade over time.
For anyone working with documents, data, or AI systems, this is worth paying attention to. The way computers read and remember text is about to change. And honestly? It’s about time.
Ready for more depth? Check out the full technical breakdown.
Why DeepSeek-OCR Is a Compression Game-Changer, Not Just OCR
OpenCraft AI is an India-based AI startup building smarter, more efficient AI solutions. We’re focused on making AI work better with real-world data. Follow our blog for more insights into emerging AI technologies explained in plain English—no jargon required.


